|
Maize Bin Viewer
Choose a region of the genome you're interested in from the image below,
or read on to find out details about this genome display.

Bin Viewer pages
|
|
Genome Browser pages
(B73 RefGen_v3)
|
What Are The Chromosome Splits Called 'Bin Boundaries' Based On?
The following explanation was submitted by Ed Coe.
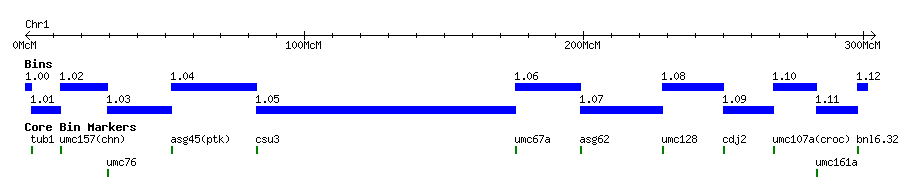
The chromosome splittings above are based on the concept of bins.
The genetic maps are divided into 100 segments, called bins, of approximately
20 centiMorgans between two fixed Core Markers (Gardiner et al. 1993 Genetics 134:917-930).
The segments are designated with the chromosome number followed by a two-digit
decimal ( e.g., 1.00, 1.01, 1.02, etc). A bin is the interval that includes
all loci from the leftmost or top Core Marker to the next Core Marker.
Placement of a locus to a bin is dependent on the precision of mapping
data, and increases in certainty as markers increase in number or
populations increase. Whenever the placement is statistically uncertain,
'Bin1' refers to the beginning of a range, and 'Bin2' refers to the end of
the range.
A Core Marker is a Locus or Probe that defines a bin
boundary (Gardiner et al. 1993 Genetics 134:917-930, Davis et al. 1999
Genetics 152(3):1137-1172).
Core Bin Marker (CBM) Assignment to V2-Curation Summary
The following explanation was provided by Jack Gardiner (April 2011).
90 CBMs were assigned to the V2 pseudomolecule assemblies.
In most cases, their locations were not significantly different from
those in V1 and the resulting changes can easily be reconciled to
improvements in the pseudomolecules. The strategy taken for V2 was
to assemble a FASTA file for each of the 10 maize chromosomes so that
this process could be done quicker for future assemblies. These files
also serve to document the EXACT sequence that was used to establish the
CBM boundaries since in many cases there were several sequences available
and they may or may not agree. In several cases (Bins 2.07/umc5a,
4.05/agrr37b, 6.02/umc59a, 10.04/umc64a) there were CBM's that were
localized on V1 that were unable to be placed on V2 and it was unclear
why they could be placed on V1 but not V2. In all cases these were RFLP
probes that hit multiple loci that tend to give complex hybridization patterns.
Further inspection indicates that some of these were placed on the assemblies
using overgo hybridization to BAC data that gives approximate placement
on the assemblies. Whatever the case may be, going forward, these CBMs
were not good choices so it was best to pick alternative markers which
were nearby and have reliable sequence. Lastly, one CBM (3.03. asg24(gts) )
was able to be placed on V2 even though it was unable to be placed on
V1 and was replaced by mus2. In V2, and future assemblies, we will
continue to use asg24(gts) since it has reliable sequence. The set of core markers
are as follows:
Table for core bin markers
Notes for table below:
|
| |
The sequence for this core bin marker could not be placed on the B73 RefGen_v3 sequence. |
| |
This Bin region used an alternative bin marker so it could be placed on
the B73 RefGen_v3 sequence. Alternate markers were selected that have empirically
confirmed positions on both genetic and physical map, and a sequence that aligns
correctly on B73 RefGen_v3.
|
|
Chr1
|
Chr2
|
Chr3
|
Chr4
|
Chr5
|
Chr6
|
Chr7
|
Chr8
|
Chr9
|
Chr10
|
|